Category: Health Sciences and Medicine
ORIGINAL
Design of a Classifier model for Heart Disease Prediction using normalized graph model
Diseño de un modelo clasificador para la predicción de cardiopatías mediante un modelo de grafos normalizados
B. Karthiga1 *, Sathya Selvaraj Sinnasamy2 *, V.C. Bharathi3 *, Azarudeen4 *, Sherubha. P5 *
1Dhanalakshmi Srinivasan Engineering College. Perambalur, India.
2SRM Institute of Science and Technology. India.
3School of Computer Science and Engineering. VIT-AP University. Amaravathi, Andhra Pradesh.
4Department of Computer Science and Engineering. Velammal College of Engineering and Technology. Madurai.
5Department of Information Technology. Karpagam College of Engineering. Coimbatore.
Cite as: Karthiga B, Sinnasamy SS, Bharathi VC, Azarudeen K, Sherubha P. Design of a Classifier model for Heart Disease Prediction using normalized graph model. Salud, Ciencia y Tecnología - Serie de Conferencias 2024; 3:653. https://doi.org/10.56294/sctconf2024653.
Submitted: 17-11-2023 Revised: 19-01-2024 Accepted: 22-03-2024 Published: 23-03-2024
Editor: Dr.
William Castillo-González ![]()
ABSTRACT
Heart disease is an illness that influences enormous people worldwide. Particularly in cardiology, heart disease diagnosis and treatment need to happen quickly and precisely. Here, a machine learning-based (ML) approach is anticipated for diagnosing a cardiac disease that is both effective and accurate. The system was developed using standard feature selection algorithms for removing unnecessary and redundant features. Here, a novel normalized graph model (n – GM) is used for prediction. To address the issue of feature selection, this work considers the significant information feature selection approach. To improve classification accuracy and shorten the time it takes to process classifications, feature selection techniques are utilized. Furthermore, the hyper-parameters and learning techniques for model evaluation have been accomplished using cross-validation. The performance is evaluated with various metrics. The performance is evaluated on the features chosen via features representation. The outcomes demonstrate that the suggested (n – GM) gives 98 % accuracy for modeling an intelligent system to detect heart disease using a classifier support vector machine.
Keywords: Heart Disease; Classification; Prediction; Machine Learning; Hyper-Parameters.
RESUMEN
Las cardiopatías son una enfermedad que afecta a una enorme cantidad de personas en todo el mundo. Especialmente en cardiología, el diagnóstico y el tratamiento de las cardiopatías deben ser rápidos y precisos. En este trabajo se propone un enfoque basado en el aprendizaje automático (ML) para diagnosticar una enfermedad cardiaca de forma eficaz y precisa. El sistema se desarrolló utilizando algoritmos estándar de selección de características para eliminar las innecesarias y redundantes. Para la predicción se utiliza un nuevo modelo gráfico normalizado (n – GM). Para abordar el problema de la selección de características, este trabajo considera el enfoque de selección de características de información significativa. Para mejorar la precisión de la clasificación y reducir el tiempo que se tarda en procesar las clasificaciones, se utilizan técnicas de selección de características. Además, los hiperparámetros y las técnicas de aprendizaje para la evaluación de modelos se han realizado mediante validación cruzada. El rendimiento se evalúa con varias métricas. El rendimiento se evalúa en función de las características elegidas mediante la representación de características. Los resultados demuestran que el (n – GM) sugerido proporciona una precisión del 98 % para modelar un sistema inteligente de detección de enfermedades cardíacas mediante una máquina de vectores soporte clasificadora.
Palabras clave: Enfermedad Cardiaca; Clasificación, Predicción, Aprendizaje Automático, Hiperparámetros.
INTRODUCTION
The most serious health problem is heart disease (HD), which has affected many people worldwide.(1) Among the most common symptoms of HD are swollen feet, muscle weakness, and shortness of breath.(2) Current methods for diagnosing cardiac disease are not useful for early identification because of a number of issues, such as accuracy and execution time.(3) Therefore, researchers are developing an effective method for detecting heart disease. Without state-of-the-art tools and trained medical personnel, diagnosing and treating heart disease can be very difficult.(4) Numerous lives can be saved by an accurate diagnosis and appropriate care.(5) According to the European Society of Cardiology, there are an estimated 26 million HD patients worldwide, and 3,6 million new cases are found each year.(6) Heart disease affects most people in the United States.(7) A doctor often diagnoses HD after patient's history review, physical exam outcomes and related symptoms. Moreover, the outcomes do not reliably identify HD. Additionally; analysis is computationally complex and challenging.(8) Creating a non-invasive system using ML classifiers is essential to address these problems. The HD is successfully predicted by the expert system using ML and ANN. The death rate is predicted based in some studies.(9,10)
Several researchers(11,12) used online available to address the HD identification issue. During testing and training, ML predictive approaches need suitable data. ML model performance improves if balanced datasets are employed for testing and training. Furthermore, the model's predictive skills are enhanced by incorporating appropriate and pertinent elements from the data. To increase model performance, data balancing and feature selection are therefore crucial. Numerous researchers have suggested different diagnosis methods in the literature, but these methods do not reliably diagnose HD. Data preprocessing is essential for data normalization, which helps machine learning models predict outcomes more accurately.(13) The authors suggested ML-based diagnosis approach for identifying HD. Various prediction models are utilized to identify HD. Some features were chosen using the current feature selection algorithms mRMR, Relief, LASSO and local features selection. Additionally, conditional mutual information features selection approach is also used. The optimum hyper-parameters are chosen with 10-fold CV technique for validation purpose.(14) Furthermore, the performance of the classifier is gauged using a range of performance measures. The HD dataset is used to evaluate the strategy. The effectiveness is evaluated in comparison to other methods.(15) However, all these techniques fail to fulfill the research requirements. The anticipated model attempts to fulfill the requirements. The study's contributions are as follows:
• The first attempt is to resolve the feature selection issues using pre-processing approaches and suitable feature selection approach. These features are provided to efficient classifiers to determine which classifier gives superior outcomes regarding accuracy and other evaluation metrics.
• To increase
prediction accuracy and shorten computation times, the authors also introduced
the novel normalized graph model (![]() )
algorithm for feature selection. The suggested algorithm's selected features
are evaluated to features chosen by the standard prevailing algorithms to see
how well the classifiers performed. Any weak dataset properties show an impact
on classifier performance.
)
algorithm for feature selection. The suggested algorithm's selected features
are evaluated to features chosen by the standard prevailing algorithms to see
how well the classifiers performed. Any weak dataset properties show an impact
on classifier performance.
• Finally, it is
suggested that the ![]() heart
disease identification may successfully identify HD.
heart
disease identification may successfully identify HD.
The study is set up like this: Section 2 offers a thorough study of the advantages and disadvantages of various strategies. The approach is described in part 3, while section 4 contains the results. Section 5's summary comes after it.
Related works
Investigators have recommended various ML approaches for HD prediction. To project the significance of various approaches, this work includes learning-based approaches that are now in use. Karthiga et al.(11) developed the HD classification system, which has a 77 % accuracy rate thanks to machine learning classification algorithms. Evolutionary and feature selection techniques are employed to the online dataset. In different investigation, Beyence et al.(12) modeled a HD prediction and categorization approach utilizing MLP and SVM algorithms and attained 80,41 % accuracy. The classification system accuracy was 87,4 %. Using enterprise miner, a statistical measurement system, an ANN-based prediction for HD was constructed by Rahman et al.(13) with sensitivity, accuracy, and specificity values of 89 %, 80 %, and 95 %. An study(14) developed a method for diagnosing HD based on ML. Both the FS algorithm and the ANN-DBP method had good results. A system of expert medical diagnosis was developed by Goel et al.(15) for the identification of HD. During the system's development, Artificial Neural Networks (ANN), Decision Trees (DT), and Navies Bays (NB) were employed as predictive machine learning models.(16,17,18,19,20) ANN obtained an accuracy of 88,12 %, NB obtained 86,12 %, and the DT classifier obtained 80 % accuracy. Jenzi et al.(21) modeled three-stage design based on ANNand achieved 88 % accuracy.
For HD diagnosis, Kalaiselvi et al.(22) created amerged medical DSS based on ANN and fuzzy model.(23,24,25,26,27,28,29,30,31) The accuracy attained was 91 %. An HD categorization using relief and rough set was proposed by Masethe et al.(32) The technique shows the classification accuracy of 92 %.
An HD identification approach utilizing feature selection and classification algorithms were proposed in.(33,34,35) Here, Sequential Backward Selection Algorithm is employed. K-NN performanceis tested on both feature set and feature subset.(36,37,38,39,40,41,42,43,44,45)
The suggested procedure produced excellent accuracy. Raju et al.(46) modeled a hybrid ML-based HD prediction in different works. Additionally, a superior approach for selecting essential features is designed from the data using ML classifiers. The accuracy rate of their classification was 88,07 %. This model was useful for several studies and develop another models.(47,48,49,50,51,52,53,54,55,56,57,58)
An improved SVM-based duality optimization technique Venkatalakshmi et al.(59) created HD detection tools. To better understand the significance of our suggested strategy, All of these technologies that are in use now use different approaches to identify HD in its early stages. Furthermore, the computation time of these approaches is high and the accuracy is low. For better treatment and recovery, HD detection needs to be improved in order to make accurate and efficient early predictions.(60,61) As such, the main problems with these earlier methods are their poor accuracy and long computation durations, which may be caused by the presence of unnecessary features in the dataset. New techniques are required for the precise identification of HD in order to address these issues. There is a great need for additional study on improving prediction accuracy.
METHOD
The proposed research is achieved by three successive steps dataset description, feature representation and normalized graph model. The anticipated model provides expert knowledge to the physicians during the crucial time and assists in predicting heart disease in earlier. The experimentation is executed in MATLAB 2020awhere metrics such as recall, precision, accuracy, and F-measure are assessed and contrasted with alternative methods. The block representation is provided in figure 1.
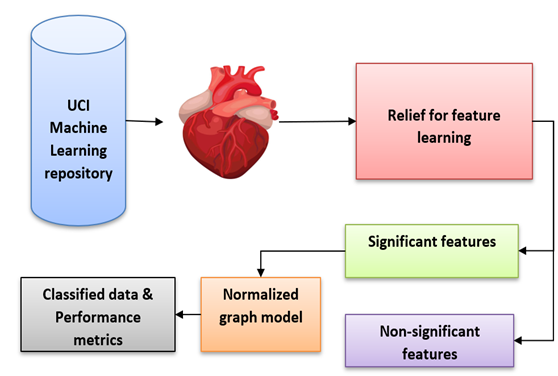
Figure 1. Block diagram
Dataset
UCI ML dataset is used for prediction purposes. When the data set was designed, only 14 subsets of the 303 occurrences and 75 attributes were used in the reported studies. Six samples were excluded from the data set owing to the missing values after pre-processing. There are 297 samples from the remaining dataset with 13-characteristics and 1- output label. Two classes on the output label indicate if HD is present or not. As an outcome, 297*13 features matrix is created. Information about the dataset matrix is provided in table 1.
|
Table 1. Dataset details |
||
|
Attributes |
Descriptions |
Type |
|
Age |
People get older |
Nom |
|
Sex |
People's gender |
Nom |
|
CP |
kind of ache in the chest , angina typical or atypical, not angular, and symptomless |
Num |
|
Tresbps |
Level of pressure |
Num |
|
Chol |
Cholesterol (serum) |
Nom |
|
FBS |
Sugar content |
Nom |
|
Resting |
ECG |
Num |
|
Thali |
cardiac rate at maximum |
Nom |
|
Exchange |
Angina during physical activity |
Num |
|
OldPeak |
Depression through exercise |
Nom |
|
Slope |
peak activity (dividend) |
Num |
|
Ca |
colored vessels in fluoroscopy |
Nom |
|
Thal |
Heart condition |
Nom |
|
Num |
Prediction Value of Disease |
Nom |
Relief for feature learning
The Relief method automatically updates the weights for each feature in the data collection. High-weight features should be chosen, while low-weight ones should be ignored. The processes used by the relief to estimate the weights of features are identical. The parameter is m, and the method is repeated through m randomly chosen training samples (Rk) without selection replacement. The "target" sample is Rk for every k, and the weight W is updated. Below is an explanation of the relief model's algorithm:
|
Algorithm 1 |
|
input: vectors with labels, or training data; the number of training samples chosen at random (m); Output: Weighted features (more feature information); 1: n → total samples of training; 2: d → total characteristics; 3: Evaluate feature set W[A]→0; 4: for k→1 to m do 5: Select target samples; // Rk 6: Predict the eligible features; 7: for A → 1 to a do 8: W[A] → W[A] - difference (A,Rk,H)/m + difference (A,Rk,H)/m 9: end for 10: end for 11: Evaluate the weighted feature vector; 12: Compute the superior feature |
Feature representation
This study introduced mutual feature information analysis to address the feature selection problem. It is a productive feature selection technique created using mutual information. The following steps are part of the designing of the algorithm. Consider the dataset D (X,Y), which, like in Eq. (1), is composed of X instances and Y output labels:
![]()
As stated in Eq. (3), we use preprocess statistical techniques such Min-Max normalization to the dataset D (X,Y):
![]()
We now use the mutual information approach D to choose the subset of feature (Xi,Yi). The feature selection approach uses the information to calculate the dataset's value for feature relevance and duplication. Conditional on the outcome of any feature chosen previously, the proposed algorithm selects features that enhances mutual information based on the target class (D). Due to the lack of certain information (output), this factor chooses characteristics that differ which are already chosen, even if it is correct independently. The balance between duplication and relevance is favourable. The feature Xn is very compatible with other features and relevant to output Y, Xj, where j∈D, according to the higher mutual information value. The condition is mathematically represented by Eq. (4):
![]()
The anticipated model attempts to balance independence and separable power among the significant features with the features selected already. The features X0 is a significant consideration if I(Y,X0 |X) is huge for every X chosen already. The foremost execution of the feature scores during the selection process evaluates the features that give more information and reduce redundancy. The model maintains the partial feature score Di which is minimal (min algorithm). The vector store of the chosen features is based on Pi.
|
Algorithm 2 |
|
Input: Input the dataset; D(X,Y) matrix, significant features, finest feature set, mutual information and partial score; Output: Select finest feature D(Xi,Yi) 1: Execute data pre-processing; 2: Chosen features as
∅ 3: for all features fi∈O do 4: Evaluate Mi; 5: Fix pi→M; 6: Fix Li→0; 7: end for 8: for k→1 to K do 9: Set scorei→0; 10: for all features, do 11: while Pi>scorek and Li<k-1 do 12: Fix Li→Li+1 13: Evaluate VUi among ok and oi; 14: Fix pi→min (pi (mutual informationik)) 15: end while 16: if pi>scorek, then 17: Fix pi>partial scorek, then 18: Choose feature subset → significant feature; 19: end if 20: end for 21: end for |
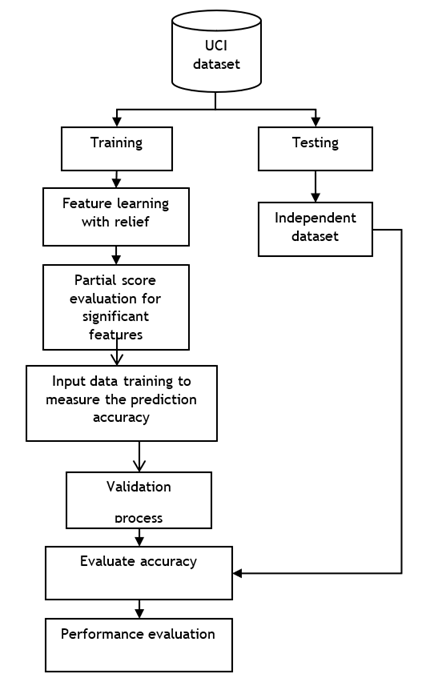
Figure 2. Flow diagram of the model
Normalized graph model
For real-time analysis, various datasets prevail in graph form, normalized to a specific format. This paper considers the proposed normalized graph model (n - GM) constructed using the graph structure. The input data product x∈RN is used to represent the spectral graph convolution, which filters the gθ= diag (θ):
gθ*x=UgθUTx (5)
Here, U refers to the matrix which is composed of normalized eigenvector graph Laplacian matrix, i.e. L=IN-D(1/2) AD(1/2)=U⋀UT, ⋀ specifies the diagonal matrix composed of L eigenvalues and UT x refers to Fourier transform (x) using is applied in Eq. (6):
![]()
Here, L ̃= 2/λmax L-IN. The normalized graph model is provided with the many convolutional layers as in Eq. (6). When k=1 is given as the total number of convolutional layers, the estimated λmax=2 is taken into account.
![]()
Moreover, over-fitting is eliminated by restricting certain parameters when the operating frequencies at every layer are reduced, as in Eq. (8):
![]()
Here, θ= θ0= - θ1 is provided in Eq. (7). However, the eigenvalue interval of IN + D1/2 AD1/2 is provided as [0, 2]. In the n-GM, the repetitive function outcomes in gradient vanishing or instability. The re-normalization idea is proposed as in Eq. (9) to address this issue:
![]()
Here, A ̃=A+IN,D ̃ii= ∑jA ̃ij. The explanation is given as follows: F feature map and filter with C channel, and input signal X∈R(N*C) (where C is Eigenvalues node dimensionality and N→total nodes):
![]()
Here, ϴ ∈ R(C*F) refers to the filter parameter matrix, and Z ∈ R(N*F) refers to the signal matrix after the convolution process. The filter complexity is O(|ε|FC). A ̃X is considered as the sparse matrix product and dense matrix.
Numerical results
This section
provides the numerical outcomes attained with the proposed ![]() and
various metrics are as precision, accuracy, sensitivity, recall, False Negative
Rate (FNR), FPR (False Positive Rate), Matthew’s correlation coefficients (MCC)
and TNR (True Negative Rate). The model significance
is determined by contrasting the suggested model with the current results.
The mathematical expressions are provided below:
and
various metrics are as precision, accuracy, sensitivity, recall, False Negative
Rate (FNR), FPR (False Positive Rate), Matthew’s correlation coefficients (MCC)
and TNR (True Negative Rate). The model significance
is determined by contrasting the suggested model with the current results.
The mathematical expressions are provided below:
Accuracy = (TP+TN)/(TP+FN+FP+TN) (12)
Precision= TP/(TP+FP) (13)
Recall/sensitivity/TPR =TP/(TP+FN) (14)
F-measure= (2*precision)/(p+r) (15)
MCC= ((TP*TN)-(FP*FN))/√((TP+FP)(TP+FN)(TN+FP)(TN+FN)) (16)
FPR=FP/(FP+TN) (17)
FNR=FN/(FN+TP) (18)
TNR=TN/(TN+FP) (19)
FPR is the wrong classification where positive prediction probabilities are not considered during testing. Additionally, the negative value likelihood that is confirmed to be negative is used to represent specificity (TNR).
|
Table 2. Proposed vs. existing comparison |
||||||||
|
Model |
Acc |
Prec |
Sensitivity |
F-measure |
MCC |
FPR |
FNR |
TNR |
|
NB |
90 % |
89 % |
85 % |
85 % |
75 % |
18 % |
25 % |
90 % |
|
LR |
94 % |
89 % |
86 % |
86 % |
78 % |
18 % |
25 % |
92 % |
|
MLP |
96 % |
89 % |
88 % |
86 % |
70 % |
13 % |
20 % |
90 % |
|
SVM |
80 % |
75 % |
55 % |
75 % |
50 % |
17 % |
55 % |
86 % |
|
DT |
85 % |
78 % |
75 % |
82 % |
65 % |
13 % |
35 % |
75 % |
|
RF |
93 % |
89 % |
80 % |
90 % |
79 % |
5 % |
25 % |
89 % |
|
L-SVM |
97 % |
98 % |
96 % |
97 % |
95 % |
7 % |
3,5 % |
97 % |
|
|
98 % |
99 % |
99 % |
98 % |
97 % |
4 % |
3 % |
98 % |
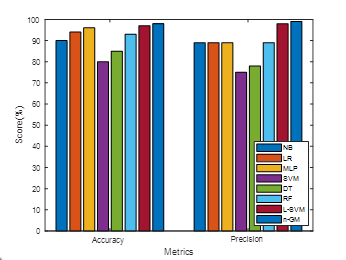
Figure 3. Accuracy and precision comparison
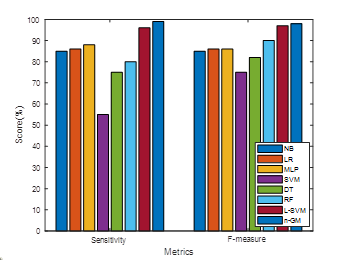
Figure 4. Sensitivity and F-measure comparison
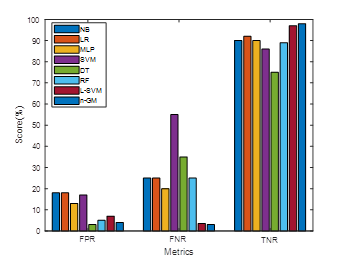
Figure 5. FPR, FNR and TNR comparison
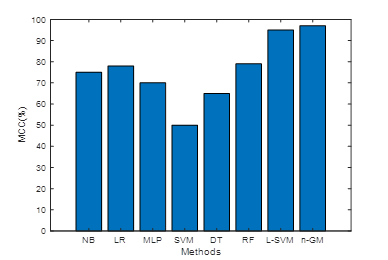
Figure 5. MCC comparison
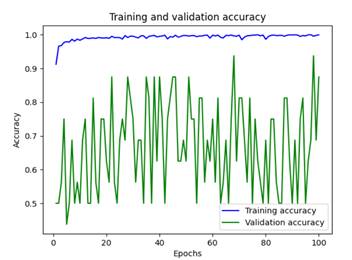
Figure 6. Training and validation accuracy
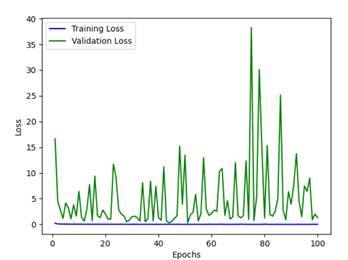
Figure 7. Training and validation loss
Table 2 compares the anticipated n-GM model with diverse approaches. Metrics such as MCC, F-measure, FPR, FNR, TNR, accuracy, sensitivity, and precision. 98 % accuracy, 99 % precision, 99 % sensitivity, 98 % F-measure, 97 % MCC, 4 % FPR, 3 % FNR, and 98 % TNR are the results obtained with the n-GM, in that order. The n-GM's precision is 8 %, 4 %, 2 %, 18 %, 13 %, 5 %, and 1 % higher than others. The n-GM's precision is 10 %, 10 %, 10 %, 24 %, 21 %, 10 %, and 1 % superior to others. The n-GM's sensitivity is 14 %, 13 %, 11 %, 54 %, 24 %, 19 % and 3 % superior to other approaches. Then-GM's F1-score is 13 %, 12 %, 12 %, 23 %, 16 %, 8 %, and 1 % superior to other approaches. The n-GM's MCC is 12 %, 19 %, 27 %, 47 %, 32 %, 18 % and 2 % superior to other approaches. The n-GM's FPR model is 14 %, 14 %, 9 %, 13 %, 9 %, 1 %, and 3 % lesser to others. The n-GM's FNR is 22 %, 22 %, 17 %, 42 %, 32 %, 22 %, and 0,5 % higher than other approaches. The TNR of the n-GM model is 8 %, 6 %, 8 %, 12 %, 23 %, 9 %, and 1 % greater than others. The n-GMperformance is superior to other (See Figure 3 to %). The anticipated n-GM is well-suited for prediction as it reduces the computational complexity. The training and validation accuracy together with the loss function are shown in Figures 6 and 7.
CONCLUSION
The results of the experiment show that, in comparison to conventional methods, the suggested feature selection methodology chooses relevant characteristics more successfully and with higher classification accuracy. Based on investigators perspective, the significant and appropriate features are exercise-induced angina and chest discomfort of the Thallium Scan kind. Some features are not a reliable indicator of the presence of heart disease, according to all algorithm results. When compared to previously proposed approaches. The accuracy of n-GM' using the proposed feature selection model is 98 % which is quite good. Additionally, the machine learning-based technique performs better than existing mining approaches. A slight increase in prediction accuracy can significantly impact the diagnosis of serious diseases. The study's originality is the creation of a system for diagnosing cardiac disease. The feature selection algorithms are newly developed to pick the features. Performance evaluation measures are employed. For testing purposes, the UCI heart disease dataset is utilized. We believe that creating a support system using ML algorithms will make diagnosing heart disease more appropriate. Utilizing feature selection algorithms to choose relevant features that enhance classification accuracy and shorten the diagnosis system's processing time is another novel aspect of our research. We'll apply additional feature selection algorithms and optimization techniques in the future to boost a prediction system's ability to diagnose HD.
REFERENCES
1. Jagtap, P. Malewadkar, O. Baswat, H. Rambade, Heart disease prediction using machine learning. Int. J. Res. Eng. Sci. Manage. 2(2) (2019)
2. Amado DPA, Diaz FAC, Pantoja R del PC, Sanchez LMB. Benefits of Artificial Intelligence and its Innovation in Organizations. AG Multidisciplinar 2023;1:15-15. https://doi.org/10.62486/agmu202315.
3. Narmadha P. Sherubha, M. Banu chitra, “Multi class feature selection algorithm for breast cancer detection”, International journal of pure and applied mathematics, pp. 301-305, 2018.
4. Batista-Mariño Y, Gutiérrez-Cristo HG, Díaz-Vidal M, Peña-Marrero Y, Mulet-Labrada S, Díaz LE-R. Behavior of stomatological emergencies of dental origin. Mario Pozo Ochoa Stomatology Clinic. 2022-2023. AG Odontologia 2023;1:6-6. https://doi.org/10.62486/agodonto20236.
5. Beyene C, Kamat P. Survey on Prediction and Analysis the Occurrence of Heart Disease Using Data Mining Techniques. International Journal of Pure and Applied Mathematics. 2018;118(8):165–74.
6. BP Sreeja, S Manoj Kumar, P Sherubha, SP Sasirekha, “Crop monitoring using wireless sensor networks”, Materials Today: Proceedings, 2020.
7. Caero L, Libertelli J. Relationship between Vigorexia, steroid use, and recreational bodybuilding practice and the effects of the closure of training centers due to the Covid-19 pandemic in young people in Argentina. AG Salud 2023;1:18-18. https://doi.org/10.62486/agsalud202318.
8. Cavalcante L de FB. Feminicide from the perspective of the cultural mediation of information. Advanced Notes in Information Science 2023;5:24-48. https://doi.org/10.47909/978-9916-9906-9-8.72.
9. Chalan SAL, Hinojosa BLA, Claudio BAM, Mendoza OAV. Quality of service and customer satisfaction in the beauty industry in the district of Los Olivos. SCT Proceedings in Interdisciplinary Insights and Innovations 2023;1:5-5. https://doi.org/10.56294/piii20235.
10. Chávez JJB, Trujillo REO, Hinojosa BLA, Claudio BAM, Mendoza OAV. Influencer marketing and the buying decision of generation «Z» consumers in beauty and personal care companies. SCT Proceedings in Interdisciplinary Insights and Innovations 2023;1:7-7. https://doi.org/10.56294/piii20237.
11. Diaz DPM. Staff turnover in companies. AG Managment 2023;1:16-16. https://doi.org/10.62486/agma202316.
12. Espinosa JCG, Sánchez LML, Pereira MAF. Benefits of Artificial Intelligence in human talent management. AG Multidisciplinar 2023;1:14-14. https://doi.org/10.62486/agmu202314.
13. Figueredo-Rigores A, Blanco-Romero L, Llevat-Romero D. Systemic view of periodontal diseases. AG Odontologia 2023;1:14-14. https://doi.org/10.62486/agodonto202314.
14. G. Jignesh Chowdary, G. Suganya, M. Premalatha, Effective prediction of cardiovascular disease using cluster of machine learning algorithms. J. Critical Rev. 7(18), 2192–2201 (2020). ISSN-2394–5125
15. Goel S, Deep A, Srivastava S, Tripathi A, "Comparative Analysis of various Techniques for Heart Disease Prediction", Information Systems and Computer Networks (ISCON) 2019 4th International Conference on. 2019. p. 88–94.
16. Gonzalez-Argote J, Castillo-González W. Productivity and Impact of the Scientific Production on Human-Computer Interaction in Scopus from 2018 to 2022. AG Multidisciplinar 2023;1:10-10. https://doi.org/10.62486/agmu202310.
17. Hernández-Flórez N. Breaking stereotypes: “a philosophical reflection on women criminals from a gender perspective". AG Salud 2023;1:17-17. https://doi.org/10.62486/agsalud202317.
18. Hinojosa BLA, Mendoza OAV. Perceptions on the use of Digital Marketing of the micro-entrepreneurs of the textile sector of the Blue Gallery in the emporium of Gamarra. SCT Proceedings in Interdisciplinary Insights and Innovations 2023;1:9-9. https://doi.org/10.56294/piii20239.
19. Jabbar MA, Deekshatulu BL, Chandra P. "Alternating decision trees for early diagnosis of heart disease," International Conference on Circuits, Communication, Control and Computing, Bangalore. 2014. p. 322–328.
20. Jabbar MA, Deekshatulu BL, Chandra P. Classification of Heart Disease using Artificial Neural Network and Feature Subset Selection. Global journal of computer science and technology. 2013.
21. Jenzi, I., Priyanka, P., Alli, P.: A reliable classifier model using data mining approach for heart disease prediction. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 3(3), 20–24 (2013)
22. Kalaiselvi, C.: Diagnosing of heart diseases using average k-nearest neighbor algorithm of data mining. In: 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom), pp. 3099–3103. IEEE (2016)
23. Karayılan T, Kılıç O, "Prediction of heart disease using neural network", Computer Science and Engineering (UBMK) 2017 International Conference on, 2017. p. 719–723.
24. Karthiga A, Mary S, Yogasini M. Early Prediction of Heart Disease Using Decision Tree Algorithm. International Journal of Advanced Research in Basic Engineering Sciences and Technology. (IJARBEST) 2017.
25. Lamorú-Pardo AM, Álvarez-Romero Y, Rubio-Díaz D, González-Alvarez A, Pérez-Roque L, Vargas-Labrada LS. Dental caries, nutritional status and oral hygiene in schoolchildren, La Demajagua, 2022. AG Odontologia 2023;1:8-8. https://doi.org/10.62486/agodonto20238.
26. Ledesma-Céspedes N, Leyva-Samue L, Barrios-Ledesma L. Use of radiographs in endodontic treatments in pregnant women. AG Odontologia 2023;1:3-3. https://doi.org/10.62486/agodonto20233.
27. Lopez ACA. Contributions of John Calvin to education. A systematic review. AG Multidisciplinar 2023;1:11-11. https://doi.org/10.62486/agmu202311.
28. M. Marimuthu, M. Abinaya, K.S. Hariesh, K. Madhankumar, V. Pavithra, A review on heart disease prediction using machine learning and data analytics approach. Int. J. Comput. Appl. (0975-8887) 181(18) (2018)
29. Maamar Bougherara, Rafik Amara, Rebiha Kemcha, IAES International Journal of Robotics and Automation (IJRA), Vol. 12, No. 4, December 2023, pp. 394 – 404
30. Marcillí MI, Fernández AP, Marsillí YI, Drullet DI, Isalgué RF. Older adult victims of violence. Satisfaction with health services in primary care. SCT Proceedings in Interdisciplinary Insights and Innovations 2023;1:12-12. https://doi.org/10.56294/piii202312.
31. Marcillí MI, Fernández AP, Marsillí YI, Drullet DI, Isalgué VMF. Characterization of legal drug use in older adult caregivers who are victims of violence. SCT Proceedings in Interdisciplinary Insights and Innovations 2023;1:13-13. https://doi.org/10.56294/piii202313.
32. Masethe, H.D., Masethe, M.A.: Prediction of heart disease using classification algorithms. In: Proceedings of the world Congress on Engineering and Computer Science, vol. 2, pp. 22–24 (2014)
33. Moraes IB. Critical Analysis of Health Indicators in Primary Health Care: A Brazilian Perspective. AG Salud 2023;1:28-28. https://doi.org/10.62486/agsalud202328.
34. N. Rajesh, T. Maneesha, S. Hafeez, H. Krishna, Prediction of heart disease using machine learning algorithms. Int. J. Eng. Technol. 7(2.32), 363–366 (2018).
35. Ogolodom MP, Ochong AD, Egop EB, Jeremiah CU, Madume AK, Nyenke CU, et al. Knowledge and perception of healthcare workers towards the adoption of artificial intelligence in healthcare service delivery in Nigeria. AG Salud 2023;1:16-16. https://doi.org/10.62486/agsalud202316.
36. Pahwa K, Kumar R. "Prediction of heart disease using hybrid technique for selecting features," 2017 4th IEEE Uttar Pradesh Section International Conference on Electrical, Computer and Electronics (UPCON), Mathura. 2017. p. 500–504.
37. Palaniappan S, Awang R. "Intelligent heart disease prediction system using data mining techniques," 2008 IEEE/ACS International Conference on Computer Systems and Applications, Doha, 2008.
38. Patel, S.B., Yadav, P.K., Shukla, D.: Predict the diagnosis of heart disease patients using classification mining techniques. IOSR J. Agric. Vet. Sci. (IOSR-JAVS) 4(2), 61–64 (2013)
39. Peñaloza JEG, Bermúdez L marcela A, Calderón YMA. Perception of representativeness of the Assembly of Huila 2020-2023. AG Multidisciplinar 2023;1:13-13. https://doi.org/10.62486/agmu202313.
40. Pérez DQ, Palomo IQ, Santana YL, Rodríguez AC, Piñera YP. Predictive value of the neutrophil-lymphocyte index as a predictor of severity and death in patients treated for COVID-19. SCT Proceedings in Interdisciplinary Insights and Innovations 2023;1:14-14. https://doi.org/10.56294/piii202314.
41. Prado JMK do, Sena PMB. Information science based on FEBAB’s census of Brazilian library science: postgraduate data. Advanced Notes in Information Science 2023;5:1-23. https://doi.org/10.47909/978-9916-9906-9-8.73.
42. Pupo-Martínez Y, Dalmau-Ramírez E, Meriño-Collazo L, Céspedes-Proenza I, Cruz-Sánchez A, Blanco-Romero L. Occlusal changes in primary dentition after treatment of dental interferences. AG Odontologia 2023;1:10-10. https://doi.org/10.62486/agodonto202310.
43. Quiroz FJR, Oncoy AWE. Resilience and life satisfaction in migrant university students residing in Lima. AG Salud 2023;1:9-9. https://doi.org/10.62486/agsalud20239.
44. Rahman M, Zahin MM, Islam L, "Effective Prediction On Heart Disease: Anticipating Heart Disease Using Data Mining Techniques", Smart Systems and Inventive Technology (ICSSIT) 2019 International Conference on. 2019. p. 536–541.
45. Rajathi S, Radhamani G. "Prediction and analysis of Rheumatic heart disease using kNN classification with ACO," 2016 International Conference on Data Mining and Advanced Computing (SAPIENCE), Ernakulam. 2016. p. 68–73.
46. Raju, C., Philipsy, E., Chacko, S., Suresh, L.P., Rajan, S.D.: A survey on predicting heart disease using data mining techniques. In: 2018 Conference on Emerging Devices and Smart Systems (ICEDSS), pp. 253–255. IEEE (2018)
47. Ramalingam V, Dandapath A, & Karthik Raja M. Heart disease prediction using machine learning techniques: a survey. International Journal of Engineering & Technology. 2018;7(2.8):684–687.
48. Roa BAV, Ortiz MAC, Cano CAG. Analysis of the simple tax regime in Colombia, case of night traders in the city of Florencia, Caquetá. AG Managment 2023;1:14-14. https://doi.org/10.62486/agma202314.
49. Rodríguez AL. Analysis of associative entrepreneurship as a territorial strategy in the municipality of Mesetas, Meta. AG Managment 2023;1:15-15. https://doi.org/10.62486/agma202315.
50. Rodríguez LPM, Sánchez PAS. Social appropriation of knowledge applying the knowledge management methodology. Case study: San Miguel de Sema, Boyacá. AG Managment 2023;1:13-13. https://doi.org/10.62486/agma202313.
51. S Rinesh, K Maheswari, B Arthi, P Sherubha, “Investigations on brain tumor classification using hybrid machine learning algorithms”, Journal of Healthcare Engineering, 2022.
52. S. Sharma, M. Parmar, Heart diseases prediction using deep learning neural network model. Int. J. Innov. Technol. Explor. Eng. (IJITEE) 9(3) (2020). ISSN 2278-3075
53. S.N. Pasha, D. Ramesh, S. Mohmmad, A. Harshavardhan, Shabana, Cardiovascular disease prediction using deep learning techniques. IOP Conf. Ser.: Mater. Sci. Eng. 981, 022006 (2020)
54. Santhana Krishnan J., Geetha S., "Prediction of Heart Disease Using Machine Learning Algorithms.", Innovations in Information and Communication Technology (ICIICT) 2019 1st International Conference on. 2019. p. 1–5.
55. Serra S, Revez J. As bibliotecas públicas na inclusão social de migrantes forçados na Área Metropolitana de Lisboa. Advanced Notes in Information Science 2023;5:49-99. https://doi.org/10.47909/978-9916-9906-9-8.50.
56. Solano AVC, Arboleda LDC, García CCC, Dominguez CDC. Benefits of artificial intelligence in companies. AG Managment 2023;1:17-17. https://doi.org/10.62486/agma202317.
57. T.K. Sajja, H.K. Kalluri, A deep learning method for prediction of cardiovascular disease using convolutional neutral network. Int. Inf. Eng. Technol. Assoc. 34(5), 601–606 (2020)
58. Thomas J, Princy RT. Human heart disease prediction system using data mining techniques. 2016 International Conference on Circuit, Power, and Computing Technologies (ICCPCT). 2016.
59. Venkatalakshmi, B., Shivsankar, M.: Heart disease diagnosis using predictive data mining. Int. J. Innov. Res. Sci. Eng. Technol. 3(3), 1873–1877 (2014)
60. Xu S, Zhang Z, Wang D, Hu J, Duan X, Zhu T. "Cardiovascular risk prediction method based on CFS subset evaluation and random forest classification framework," 2017 IEEE 2nd International Conference on Big Data Analysis (ICBDA), Beijing. 2017.
61. Yi-Chang Wu, Yao-Cheng Liu, Ru-Yi Huang, The use of artificial intelligence in interrogation: lies and truth”, IAES International Journal of Robotics and Automation (IJRA), Vol. 12, No. 4, December, 2023, pp. 332~340
FINANCING
The authors did not receive funding for the development of this research.
CONFLICT OF INTEREST
The authors declare that there is no conflict of interest.
AUTHORSHIP CONTRIBUTION
Conceptualization: B. Karthiga, Sathya Selvaraj Sinnasamy, V.C. Bharathi, Azarudeen, Sherubha. P
Research: B. Karthiga, Sathya Selvaraj Sinnasamy, V.C. Bharathi, Azarudeen, Sherubha. P
Writing-original draft: B. Karthiga, Sathya Selvaraj Sinnasamy, V.C. Bharathi, Azarudeen, Sherubha. P
Writing-review and proof editing: B. Karthiga, Sathya Selvaraj Sinnasamy, V.C. Bharathi, Azarudeen, Sherubha. P