Categoría: STEM (Science, Technology, Engineering and Mathematics)
ORIGINAL
An efficient fake news classification model based on ensemble deep learning techniques
Un modelo eficiente de clasificación de noticias falsas basado en técnicas de aprendizaje profundo ensemble
R. Uma Maheswari1 *, N. Sudha1 *
1Department of Computer Science, Bishop Appasamy College of Arts and Science. Coimbatore, Tamil Nadu 641018, India.
Cite as: Maheswari RU, Sudha N. An efficient fake news classification model based on ensemble deep learning techniques. Salud, Ciencia y Tecnología - Serie de Conferencias 2024; 3:649. https://doi.org/10.56294/sctconf2024649
Submitted: 04-12-2023 Revised: 13-02-2024 Accepted: 09-03-2024 Published: 10-03-2024
Editor: Dr.
William Castillo-González ![]()
ABSTRACT
The availability and expansion of social media has made it difficult to distinguish between fake and real news. Information falsification has exponentially increased as a result of how simple it is to spread information through sharing. Social media dependability is also under jeopardy due to the extensive dissemination of false information. Therefore, it has become a research problem to automatically validate information, specifically source, content, and publisher, to identify it as true or false. Despite its limitations, machine learning (ML) has been crucial in the categorization of information. Previous studies suggested three-step methods for categorising false information on social media. In the first step of the process, the data set is subjected to a number of pre-processing processes in order to transform unstructured data sets into structured data sets. The unknowable properties of fake news and the features are extracted by the Lexicon Model in the second stage. In the third stage of this research project, a feature selection method by WOA (Whale Optimization Algorithm) for weight value to tune the classification part. Finally, a Hybrid Classification model that is hybrid with a fuzzy based Convolutional Neural Network and kernel based support vector machine is constructed in order to identify the data pertaining to bogus news. However using single classifier for fake news detection produces the insufficient accuracy. To overcome this issue in this work introduced an improved model for fake news classification. To turn unstructured data sets into structured data sets, a variety of pre-processing operations are used on the data set in the initial phase of the procedure. The unknowable properties of fake news and the features are extracted by the Lexicon Model in the second stage. In the third stage of this research project, a feature selection method by COA (Coati Optimization Algorithm) for weight value to tune the classification part. Finally, an ensemble of RNN (Recurrent Neural Networks), VGG-16 and ResNet50.A classification model was developed to recognise bogus news information. Evaluate each fake news analysis’ performance in terms of accuracy, precision, recall, and F1 score. The suggested model, out of all the methodologies taken into consideration in this study, provides the highest outcomes, according to experimental findings.
Keywords: Fake News Classification; Whale Optimization Algorithm; Lexicon Model; Ensemble Learning.
RESUMEN
La disponibilidad y expansión de las redes sociales ha dificultado la distinción entre noticias falsas y reales. La falsificación de información ha aumentado exponencialmente como consecuencia de lo sencillo que resulta difundir información compartiéndola. La fiabilidad de los medios sociales también está en peligro debido a la amplia difusión de información falsa. Por ello, se ha convertido en un problema de investigación validar automáticamente la información, en concreto la fuente, el contenido y el editor, para identificarla como verdadera o falsa. A pesar de sus limitaciones, el aprendizaje automático (AM) ha sido crucial en la categorización de la información. Estudios anteriores propusieron métodos de tres pasos para categorizar la información falsa en las redes sociales. En el primer paso del proceso, el conjunto de datos se somete a una serie de procesos de preprocesamiento para transformar conjuntos de datos no estructurados en conjuntos de datos estructurados. En la segunda etapa, el modelo de léxico extrae las propiedades desconocidas de las noticias falsas y sus características. En la tercera etapa de este proyecto de investigación, un método de selección de características por WOA (Whale Optimization Algorithm) para el valor de peso para afinar la parte de clasificación. Por último, se construye un modelo de clasificación híbrido con una red neuronal convolucional basada en fuzzy y una máquina de vectores de soporte basada en kernel para identificar los datos pertenecientes a noticias falsas. Sin embargo, el uso de un único clasificador para la detección de noticias falsas produce una precisión insuficiente. Para superar este problema, en este trabajo se introduce un modelo mejorado para la clasificación de noticias falsas. Para convertir conjuntos de datos no estructurados en conjuntos de datos estructurados, se utilizan diversas operaciones de preprocesamiento en el conjuntode datos en la fase inicial del procedimiento. En la segunda fase, el modelo de léxico extrae las propiedades desconocidas de las noticias falsas y sus características. En la tercera etapa de este proyecto de investigación, un método de selección de características por COA (Coati Optimization Algorithm) para el valor de peso para afinar la parte de clasificación. Por último, se desarrolló un conjunto de RNN (Redes Neuronales Recurrentes), VGG-16 y ResNet50.Un modelo de clasificación para reconocer la información de noticias falsas. Se evaluó el rendimiento de cada análisis de noticias falsas en términos de exactitud, precisión, recall y puntuación F1. El modelo sugerido, de entre todas las metodologías tomadas en consideración en este estudio, proporciona los resultados más altos, de acuerdo con los hallazgos experimentales.
Palabras clave: Clasificación de Noticias Falsas; Algoritmo de Optimización Whale; Modelo Léxico; Aprendizaje Ensemble.
INTRODUCTION
Access to information has been easier because to recent developments in communication and mobile technologies, as well as the widespread usage of the Internet. The uncontrolled growth of web-based life apps and the competition among international organisations to exchange and broadcast news information in the sphere of social communication have also had an impact on the accuracy of the data. Social media platforms have recently risen to prominence as important information providers. Low price, quick access, simplicity of use, and availability across all digital platforms, including computers, cellphones, iPods, and other devices, are crucial aspects in the market be unique.(1,2)
Fake news implies spread of false information on social media with the intention of confusing or misinforming readers in order to further commercial or political objectives.(3) Additionally, the sector of news authoring and distribution is seeing an increase in a variety of players, which has produced news articles that are hard to determine whether they are legitimate or not. Researchers from academia and business are searching for solutions to halt the massive dissemination of false information on social media.(4,5)
The extensive use of fake news leading up to the 2016 US presidential election is thought to be a contentious subject that influences public opinion.(6) The propagation of false information on social media at an accelerated rate significantly raises the possibility of a catastrophic effect. As a result, the transmission of false information is a worldwide issue, and several nations have made it illegal to produce and disseminate false information online. Current content-based analytics techniques are thought to be challenged by the automatic detection of fake news.(7)
There is an urgent need to develop ML approaches to detect fake news. Other methods for detecting false news have also been employed, along with traditional and deep learning (DL) models.(8,9) These techniques may be divided into three groups based on their content, social context, and transmission. Due to their unique feature extraction abilities, existing neural network models have beaten conventional models in terms of performance, but these techniques are still unable to identify bogus news, breaking news, and emergency situations.(10)
A three-step method for categorising false information on social media was presented in order to circumvent this issue in previous research. In the first step of the process, the data set is subjected to a number of pre-processing processes in order to transform unstructured data sets into structured data sets. The unknowable properties of fake news and the features are extracted by the Lexicon Model in the second stage. In the third stage of this research project, a feature selection method by WOA for weight value to tune the classification part. Finally, a HYbrid Classification model that is hybrid with a fuzzy based Convolutional Neural Network and kernel based support vector machine is constructed in order to identify the data pertaining to bogus news. However using single classifier for fake news detection produces the insufficient accuracy.
To overcome this issue in this work introduced an improved model for fake news classification. To turn unstructured data sets into structured data sets, a variety of pre-processing operations are used on the data set in the initial phase of the procedure. The unknowable properties of fake news and the features are extracted by the Lexicon Model in the second stage. In the third stage of this research project, a feature selection method by COA for weight value to tune the classification part. Finally, an ensemble of Recurrent Neural Network(RNN), VGG-16 and ResNet50classification models is constructed in order to identify the data pertaining to bogus news.
Related works
Jain et al.(11) shown ways of identifying bogus news with their proposed model. In an effort to aggregate news, ML and natural language processing (NLP) were used. Support Vector Machine (SVM) then identifies whether the news is authentic or fraudulent. The suggested models outcomes were compared with other models where the suggested model functioned effectively and could predict results with an accuracy of up to 93,6 %.
Mandical et al.(12) proposed a method that is capable of accurately categorising false news is an attempt to speed up identifications of fake news. ML techniques including Naive Bayes (NB), Active Passive Classifier, and Deep Neural Network were used on eight different datasets collected from various sources. This work also included analysis and results of models. The use of appropriate models and techniques can reduce burdens of identifying fake news.
PCA (Principal component analysis) and chi squared were utilized by Umer et al.(13) in tandem with hybrid neural network architecture, which blends CNN and LSTM capabilities. This work proposes to use dimensionality reduction techniques to reduce the sizes of feature vectors before sending them to the classifier. In order to construct the logic, this study employed a dataset from the Fake News Challenge website with four different forms of positions: agree, disagree, debate, and irrelevant. More contextual characteristics for fake news identification are provided by transferring non-linear variables to PCA and chi-square. The goal of this inquiry was to determine an article's position with respect to its title. The accuracy and F1 scores of the suggested model increase results by approximately 4 % and 20 %, respectively. With an accuracy of 97,8, the experimental findings demonstrate that PCA works better than the peak approach and the Chi-squared method.
A synthetic classification model to identify fake news was proposed by Hakak et al.(14) and the model showed more accuracy than the current model. The suggested approach takes significant elements from the fake news dataset, and subsequently classifies the retrieved characteristics using an aggregate model composed of three popular machine learning models: decision trees, random forests, and additional tree classification. We obtained training and test accuracy of 99,8 % and 44,15 % on the Liar dataset, respectively. For the IOT dataset, we achieved 100 % training and testing accuracy.
Khalil et al.(15) presented the first significant library of Arabic fake news, which included 606 912 pieces gathered from 134 Arabic-language internet news sites. The reliability, unreliability, and ambiguity of news sources are classified using an Arabic fact-checking tool. Additionally, several ML techniques are used to the detection job. DL models outperform more conventional ML models, according to tests. The missing and overmatched pages issues in the model training suggest that the corpus is still noisy and challenging.
Granik et al.(16) suggested a straightforward Bayesian classifier technique to identify bogus news. This strategy is put into practise as a software system and examined using a sample of Facebook news postings. Given the relative simplicity of the model, we were able to attain a classification accuracy of roughly 74 % on the test set. Several methods, which are also covered in the article, can be used to enhance these outcomes. The findings gained demonstrate that using artificial intelligence techniques, the issue of identifying bogus news may be resolved.
Saleh et al.(17) Describe the OPCNN-false model of an optimised convolutional neural network for the detection of fake news. Using four point datasets representing fake news standards, the performance of OPCNN-FAKE is compared to that of RNN, LSTM (Long Short Term Memory), and six classical ML techniques: DT (Decision Tree), LR (Logistic Regression), KNN (K Nearest Neighbour), RF (Random Forest), SVM, and NB. Mesh search and hyperopt optimisation techniques were used to optimise parameters of ML and DL . In addition, N-grams and Term Frequency—Inverse Document Frequency (TF-IDF) were used to extract features from the reference dataset for classical machine learning while integrating from Gloves. Hand is used to represent features as a feature matrix for DL models. The results were validated using accuracy, precision, recovery, and F1 measurement to evaluate OPCNN-FAKE's performance. The outcomes demonstrate that, when compared to other models, the OPCNN-FAKE model performs the best for each set of data. Additionally, OPCNN-false outperforms other models in test and cross-validation results, showing that it is substantially more effective than other models in identifying fake news.
Proposed methodology
The suggested model is covered in detail in this section. The proposed model is divided into four phases: preprocessing, feature extraction based on the Lexicon Model, feature selection via the Coati Optimisation Algorithm, and ensemble learning for fake news detection based on the Recurrent Neural Network (RNN), VGG-16, and ResNet50 models. Overall architecture of the proposed model is shown in figure 1.
Data Collection
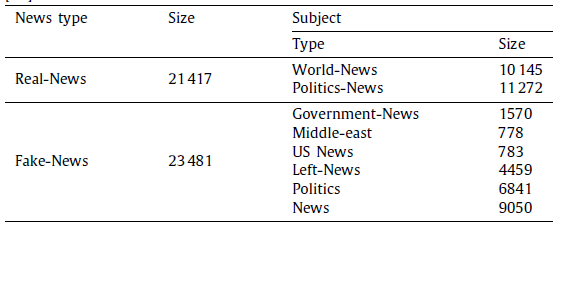
The datasets that were utilized in this research are publicly accessible and may be downloaded at no cost online. The information comes from a variety of sources and contains both fake and genuine news stories. While fake news websites make untrue claims, legitimate news reports accurately describe events. Politifact.com and Snopes.com are useful for fact-checking, many of those publications' political statements may be carefully examined for consistency. The "ISOT Fake News Dataset", which includes both real and fraudulent items pulled from the Internet, is the dataset utilized in this research. The real stories come from reuters.com, a well-known news website, while the false ones originate from a variety of sources, mostly from sites that politifact.com classifies as frauds. There are 44 898 articles in all, 21 417 of which are accurate, and 23 481 of which are false. The entire database contains articles on a range of subjects, but political news is the most popular one.
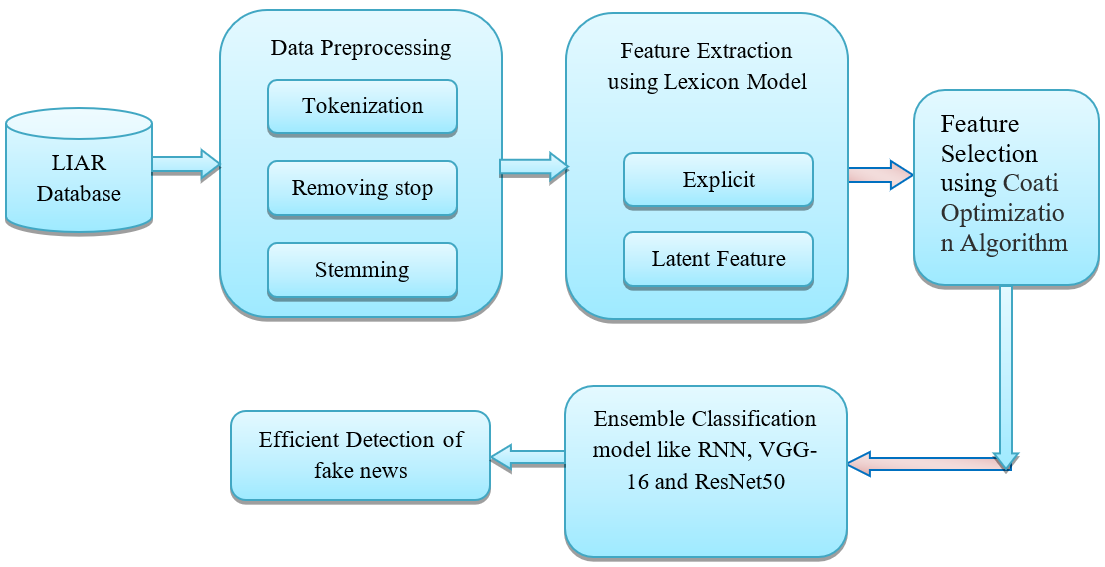
Figure.1 The suggested Model’s overall architecture
Data Pre-processing
Before training and analyzing the data using a model, pre-processing the data is often the initial step. The quality of ML algorithms depends on the data they are fed. For there to be enough consistency to provide the best outcomes, it is essential that data be structured correctly and that important characteristics be included. As shown in, normalizing picture inputs and dimensions reductions are only two of the several stages involved in pre-processing the data for computer vision ML algorithms. They are intended to reduce some of the insignificant details that serve as visual cues for various images. The job of identifying the picture does not benefit from features like brightness or darkness. Similar to this, certain text passages are useless for determining if a passage is authentic or not.
Tokenization
As part of the tokenization process, all punctuation is removed from the textual data and the provided text is divided into tokens, or smaller units. In order to exclude phrases that include numbers, the number filter has been implemented. To change text data to lowercase or uppercase, the case converter has been employed. All of the words have been changed to lowercase in this document. Last but not least, the words with less than N characters have been removed in this phase using the N-chars filter.
Stop-words removal
While they are commonly employed to finish sentences and link phrases, stop words are not crucial terms. Language-specific terms, these ones don't convey any knowledge. Prepositions, pronouns, and conjunctions are examples of stop words. There are between 400 to 500 stop words in English. Stop words include terms like "a," "five," "about," "by," "but," "this," "done," "on," "above," "once," "then," "until," "again," "when," "where," "what," "everything," "me and," "anyone," "against," etc.
Stemming
This procedure reduces a word's various grammatical forms to its fundamental form. Finding the fundamental form of words with the same meaning but distinct word forms is a process known as root finding. For instance, words like "connected", "connected", "connected", "connected", and "connected" can be used to create the phrase "connected". Preprocessing steps for data are included in Algorithm 1.
Algorithm 1. Preprocessing process
Input: Given textual data
Output: Pre processed data
1. Textual data without numbers
2. Remove all punctuation from text data
3. Characters with the character < N should be filtered out
4. Convert textual data's case
5. Delete all stop words
6. Stem textual data
Feature Extraction
The characteristics will be extracted after preprocessing. Reducing the amount of resources needed to explain a big data collection is the goal of feature extraction. One of the primary issues when analysing complicated data is the sheer volume of variables. An analysis with a lot of variables frequently needs a lot of memory and processing resources. Additionally, it may result in the classification system being overfit to training examples and having trouble generalising to new samples. A way of creating combinations of variables that avoid these issues while accurately characterising data is known as feature extraction. We concentrate on the lexical model for the feature extraction idea in the proposed study.
LexiconModel
About 6 300 terms are included in the built-in vocabulary. It was personally made with the help of Vader Sentiment as a guide. The emotional values of each word in the lexicon range from 100 (the most positive) to 100 (the least positive). According to empirical research, some positive and negative words can occasionally emerge in sentences with a neutral meaning. Alternatively we estimate a conditional probability P) as shown in the equation for each word in the lexicon. First:
p (positive![]()
p (negative![]() (1)
(1)
For each positive phrase, the likelihood that a random message containing this word is positive is assessed using a labelled data set. For each negative term, the likelihood is also evaluated. And to see if using this knowledge in the process of emotional categorization may assist in dealing with messages that include mixed emotions (both positive and negative). Random selection is used to choose a sample of 100 000 good and 100 000 negative news stories. The frequency of each word in the lexicon, represented by the letter w, is then determined for the chosen positive and negative messages. The conditional probability is computed as given in the equation based on positivity or negativity of words.
p (positive![]() =
=![]() =
=![]() (2)
(2)
p (negative![]() =
=![]() =
=![]() (3)
(3)
Where #wP and #wN stand for message counts from the sample that contains word w and are positive and negative, respectively. To calculate the likelihood of positive and negative words, respectively, two formulae are utilised. This method is done numerous times to provide more precise findings, and the vocabulary contains the average probability that was found for each word. the likelihood that the data will be sent to the next associative classification model.
Feature Selection using Coati Optimization Algorithm (COA)
COA is a recently suggested meta-heuristic algorithm that mimics the properties of natural coatis. The fundamental purpose of COA is to mimic two essential coati behaviours: approaching and hunting iguanas, as well as dodging hunters. Coatis, sometimes known as coatimundis, are omnivorous animals that eat small vertebrates as well as invertebrates. Notably, a sizable portion of the coatis' diet consists of green iguana. Owing to their arboreal lifestyle, coatis usually hunt in groups and scavenge for iguanas in trees. When the coatis hunt, some members of the group may climb trees to frighten the iguana into jumping to the ground, while others may move quickly to attack it. Nevertheless, coatis are susceptible to assaults from hunters and huge raptors despite their successful predation strategies. The COA algorithm aims to simulate the coatis’ behaviors. The following subsec2ons summarize the mathematical model of COA algorithm.
Stage 1: initialization
Each coati’s location in the search space corresponds to the decision variable values, and each location is a suggested solution to the optimization problem. The COA begins by randomly initializing the coatis’ positions in the search space using equation 4.
![]() .
.![]() ,i=1,2,…..M,j=1,2,….,n. (4)
,i=1,2,…..M,j=1,2,….,n. (4)
Where Pi represents the placement of ith coati insearch space; pi,j refers to the jth dimension.Pmaxjand Pminj define the upper and lowerbounds of the jthdimension respectively, andrandom() generates a random real number between 0 and 1. Equation 5 shows a populationmatrix of the coatis.
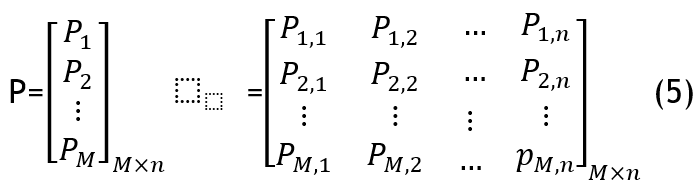
Coatis use this matrix to update their positions. Each location is a possible solution, and it is evaluated by using an objective function as shown in equation 6.
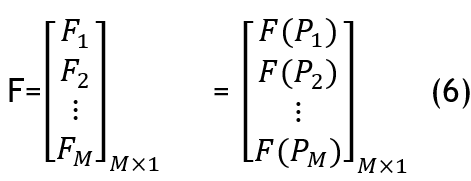
Where F represents a vector of the computed objective function and Fi, where i= {1, 2, ..., M}is the value obtained using objective function according for the ith coati.
Stage 2-exploration: a strategy for hunting and attacking iguanas
This stage simulates a collection of coatis climb a tree with the intent to intimidate an iguana, while some remain on the ground awaiting the moment when the iguana falls. Once the iguana falls, the coatis attack and hunt it. This strategy allows the coatis to explore various locations in the search space, which showcases their ability to explore globally when solving problems. The COA algorithm assumes that the optimal coati of the population is located at the same location as the iguana. In addition, it is supposed that fifty percent of the coatis are ascending the tree, while the others are patiently waiting for the iguana to plummet to the earth. To mathematically simulate the position of the coatis climbing up the tree, Equation 7 is utilized.
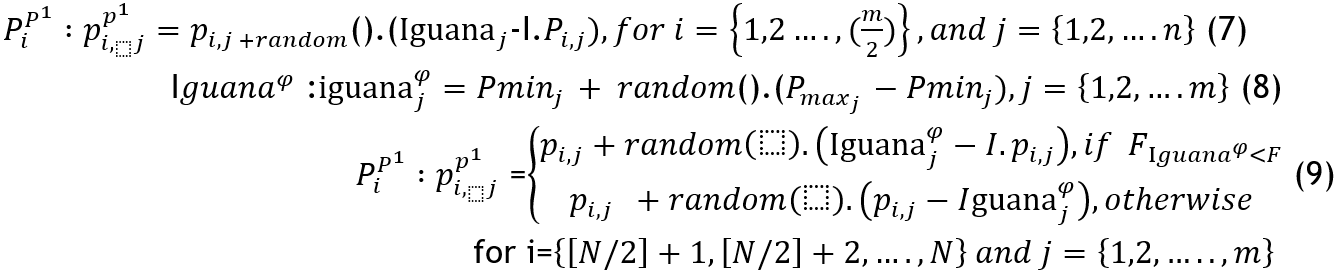
Where random()
generates a random real number between 0 and 1. The position of the best
member, Iguana, in the search space is represented by the variable ’Iguana’,
with its jth dimension being Iguanaj . An integer ’I’
is randomly picked from the set {1,2}. The location of the iguana on the ground
is randomly computed and represented by Iguana![]() , with its jth dimension being
, with its jth dimension being ![]() and its objective function value being
and its objective function value being ![]() The floor func2on (also called greatest integer function) is
denoted by [.].
The floor func2on (also called greatest integer function) is
denoted by [.].
If the new location of each coati leads to an improvement in the objective function value, then it is considered acceptable for the update process. However, if there is no improvement, the coati will remain in its previous location. This condition applies to all N coatis, which is simulated using equation 8.
![]()
The ith coati’s
new location,![]() is computed using the value of its jth dimension,
is computed using the value of its jth dimension,![]() and itsobjective function value,
and itsobjective function value, ![]() .
.
Phase 3-exploitation: a process of escaping from predators
This stage of updating coatis’ location in the search space is designed to imitate coatis’ natural behavior when facing hunters and fleeing from them. When a predator attacks a coati, it quickly moves away from its current location to a safer one. Coatis move in such a way as to end up in a secure location close to their current location, demonstrating their proficiency in finding local solutions. In order to imitate the coatis’ behavior, a new location is created randomly near their present position using Equations 11 and 12.
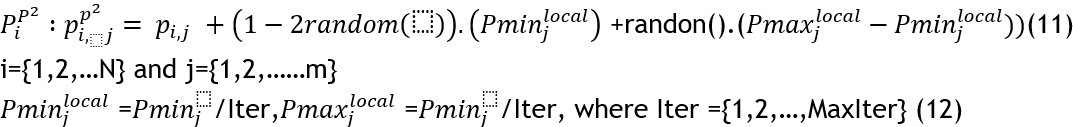
If the value of the objective function enhances, which is represented by equation 11, then the recently computed location is considered satisfactory.
![]()
Where ![]() represents the updated position ofthe ith coati computed
during this stage of COA.
represents the updated position ofthe ith coati computed
during this stage of COA.
Its jth dimension
is denoted as ![]() and itsobjective function value is represented by
and itsobjective function value is represented by ![]() random() generates random numbers in the interval [0,1]
along with iteration counters ”Iter”.
random() generates random numbers in the interval [0,1]
along with iteration counters ”Iter”. ![]() and
and ![]() represent the local lower and upper bounds of the jth decision
variable, respectively. Similarly,
represent the local lower and upper bounds of the jth decision
variable, respectively. Similarly, ![]() and
and ![]() refer to the lower and upper bounds of the jth decision
variable, respectively.
refer to the lower and upper bounds of the jth decision
variable, respectively.
Repetition process
The completion of an iteration of COA occurs once all coatis in the search space have had their positions updated according to the second and third stages. The population is then updated using Equations 5 through 11 and the process is repeated until the final iteration of the algorithm. At the end of the entire COA run, the output returned is the best solution obtained overall iterations.
Start COA
1. Enter information about the optimization problem.
2. Determine iteration counts T and overlay counts N.
3. Initialize the positions of all overlays according to Equation 1 and evaluate the objective function for this initial population.
4. For t =1:T
5. Update the location of the iguana based on the location of the best member of the population
6. Phase 1: Iguana hunting and attacking strategy (Discovery phase)
7. For i=1:⌊N/2⌋
8. Compute new positions for ith layers using equation (6)
9. Update the position of the ith layer using equation (9)
10. End for
11. Phase 2: Predator escape process (exploit phase)
12. Compute local limits of variables using equation (10)
13. For i=1:N
14. Compute positions of ith layers using equation (10)
15. End for
16. Save best candidate solutions uobtained so far
17. End for
18. Output best solutions obtained by COA for the given problem.
19. Terminate COA execoutiuon.
Classification using Ensemble DL(EDL)
After feature selection classification is done in this work using Ensemble of RNN , VGG16 and ResNet50.
RNN
The standard feedback neural network is extended by a layer of artificial neural networks called RNN. RNN, unlike feedback neural networks, can process successive inputs as it contains recurrent hidden states which are activated at steps based on prior steps. This is one way that the network might exhibit dynamic behaviour over time.(18,19) A conventional RNN model consists of three layers: an input layer, a hidden layer (core network), and an output layer (see Figure 2). Processing units (neurons) of the hidden layer are linked to one another by weighted synapses (connection weights).
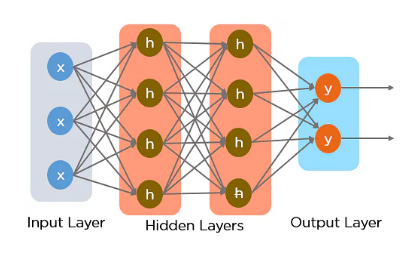
Figure 2. Recurrent Neural Network
VGG-16 model
According to figure 3, the VGG16 model is a convolutional neural network model with thirteen convolutional layers. (C1, C2, C3 through C13) as well as FC-6, FC-7, and FC-8, three completely linked layers. In order to enhance depth, the VGG16 lattice contour only employs convolutional layers with 3 x 3 kernel sizes. The first convolutional layer's feed input in the pre-trained model is sent through a stack of convolutional layers (13 convolutional layers) with a kernel size of three by three. The pooling layer is followed by many convolutional layers, max with 2x2 filter size. The three layers are fully linked after configuring all of the convolutional layers, and then various depths in various formats are applied. The first two layers have 4096 channels total and are fully interconnected, whereas the third FC layer uses 1000-way ILSVRC classification and has 1 000 channels.(20,21)
![]()
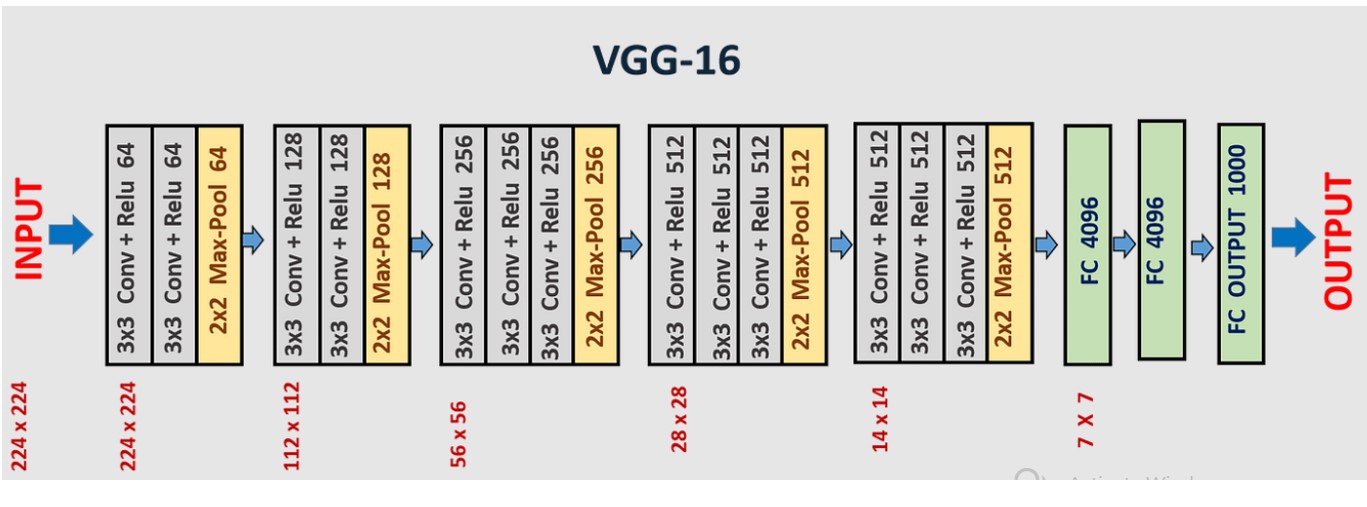
Figure 3. VGG-16 architecture
ResNet50
ResNet-50 is a ResNet version with 50 layers (48 convolutional layers, 1 MaxPool layer, and 1 average group layer) as shown in figure 4, ResNet-50 transmits three distinct layer types. Reducing connections instead of using convolutional layer blocks is the basic idea underlying residual networks, or ResNets. The "bottleneck" that acts as the building block is governed by two simple design principles: layers with the same number of filters for the same output feature map size, and the number of filters will double if the feature map size is halved.(22,23) Figure 3 shows the ResNet-50 architecture.
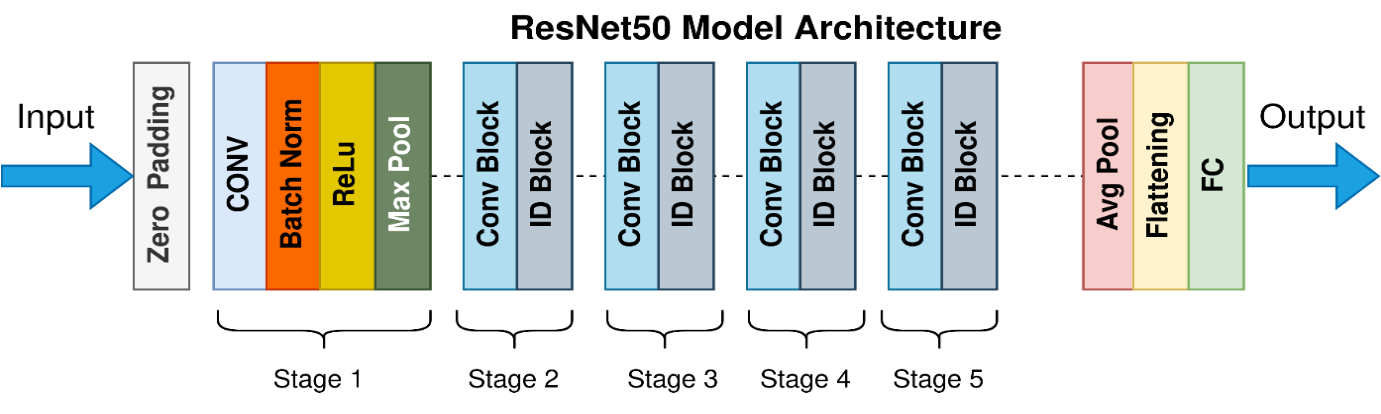
Figure 4. ResNet-50 architecture
Ensemble learning using MV (Majority Votes)
MVs are decision-making techniques that have been retrieved from RNN, VGG-16, and Resnet-50 classifiers that have been run n times, independently, and disaggregated, producing additional options each time. Assume that N examples make up set, and Q classes make up set C. Let us define an algorithm set S = {A1, A2, AM} which contains the M classifiers used for the voting. Each example x ∈ χ is assigned to have one of the Q classes. The time classifier will generate a distinct forecast for every case. Each instance is finally classified according to the classification that most classifiers (those with the highest votes) anticipated for that particular occurrence. Each vote in the MV is given a weight based on the Acc value of the classifier's prediction accuracy. A class ck's total votes are equal to:
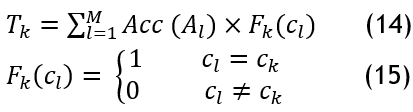
Where, cl and ck are C’s classes. Courses with highest weights are selected. The highest classification rates for classifying data as positive and negative were obtained overall when all classifiers were trained on various independent training sets and given weights.
RESULTS AND DISCUSSION
This model is implemented in Matlab. This work uses the ISOT fake news dataset to train ensemble learning models. This work considers the existing CSI, CNN, HFEM-CNN and WOA-HYC and the proposed EDLfor assessing performance measures, including f1 score, accuracy, precision, and recall. Real and fraudulent news pieces are both included in the collection. Table 1 shows the article size and kind by category for the ISOT Dataset.
Table 1. Article size and kind by category for the ISOT Dataset
Evaluation metrics
The proportion of properly identified positive observations to all of the anticipated positive observations is what is referred to as precision.
|
Precision = TP/TP+FP |
(16) |
The proportion of properly detected positive observations to all observations is known as the sensitivity or recall ratio.
|
Recall = TP/TP+FN |
(17) |
The weighted average of both Precision and Recall is known as the F-measure. Because of this, it considers false positives and false negatives.
|
F1 Score = 2*(Recall * Precision) / (Recall + Precision) |
(18) |
These are the positives and negatives used to calculate accuracy:
|
Accuracy = (TP+FP)/(TP+TN+FP+FN) |
(19) |
Where TP-represents True Positive, TN represents True Negative, FP refers False Positive and FN refers False Negative.
|
Table 2. Performance comparison results |
|||||
|
Metrics |
Methods |
||||
|
CSI |
CNN |
HFEM-CNN |
WOA -HYC |
EDL |
|
|
Accuracy |
84,14 |
88,60 |
90,21 |
92,99 |
95,17 |
|
Precision |
85,25 |
87,61 |
90,90 |
93,71 |
96,07 |
|
Recall |
82,34 |
87,94 |
89,04 |
92,08 |
94,21 |
|
F –measure |
83,19 |
87,77 |
89,96 |
92,89 |
95,13 |
|
Error rate |
15,86 |
11,39 |
9,78 |
7,00 |
4,82 |
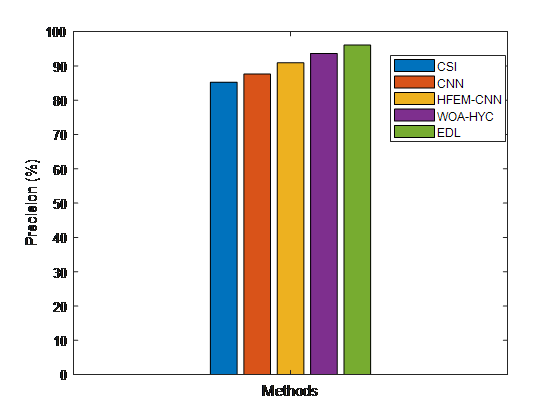
Figure 5. Depicts comparative values of precision for false news detections between suggested and existing methods
Figure 5 compares the effectiveness of suggested and existing false news detection methods. The findings demonstrate that the suggested EDL approach produces results with excellent accuracy when compared to the existing classification methods.
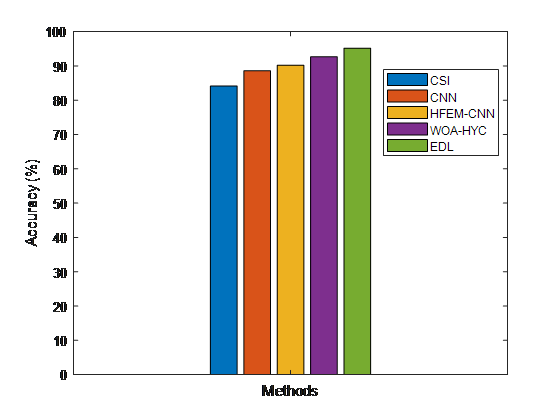
Figure 6. Depicts comparative values of accuracy for false news detections between suggested and existing methods detection methods
Figure 6 compares the proposed and current fake news detection methods' accuracy ratings. The suggested EDL technique beats the existing classification algorithms in terms of accuracy, according to the results.
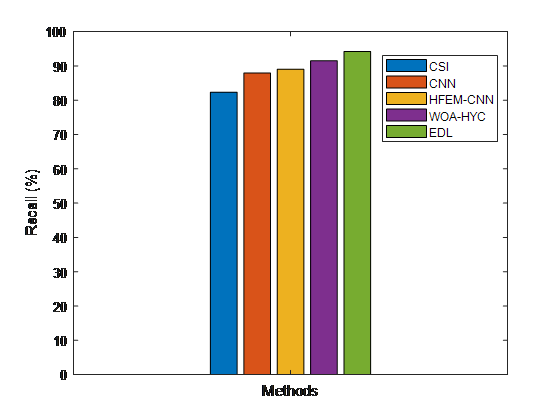
Figure 7. Compares the recall outcomes of proposed and existing fake news detection methods
Figure 7 displays the recall comparisons between suggested and existing fake news detection methods. The suggested EDL technique performs better on the recovery side than the already employed classification algorithms, according to the results.
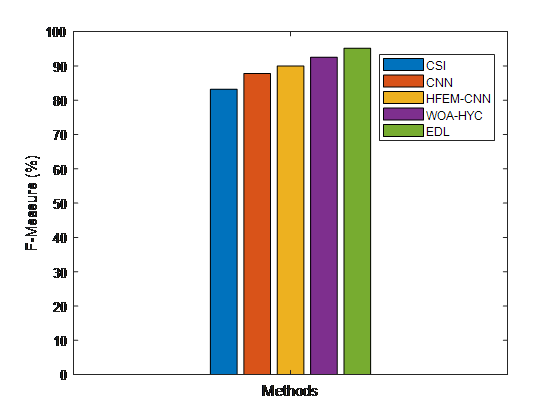
Figure 8. Depicts comparative f-measure values for false news detections between suggested and existing methods detection methods
Figure 8 displays a comparison of proposed and current F-metric fake news detecting methods. The suggested EDL approach outperforms the analytical methods, according to the results. The F-metric was used to determine the groupings.
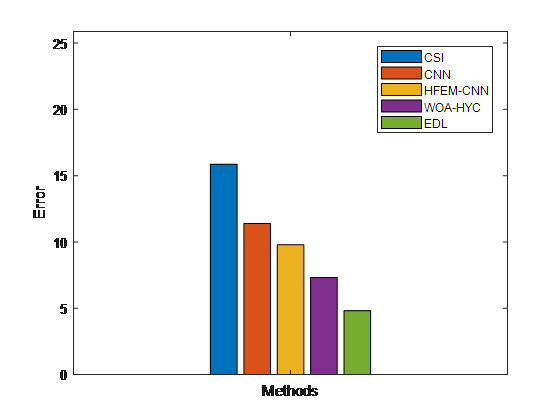
Figure 9. Compares the error rate outcomes of proposed and existing fake news detection methods
Figure 9 compares the proposed and current fake news detection methods' error rate ratings. The suggested EDL technique beats the existing classification algorithms in terms of error rate, according to the results.
CONCLUSION
Information collection through social networks is like wielding a two-edged sword. On the one hand, it is simple to use, quick to access, easy to forward to socially significant material, and offers a variety of viewpoints on distinctive and current information. each minute. Conversely, a variety of websites alter content based on personal tastes or opinions. Fake news is edited or erroneous information that is shared on social media with the intent to harm an individual, community, or organisation. This work aimed to provide an improved model for fake news detection. In which pre-processing steps like tokenization, removing stop and stemming are done. Features are extracted using Lexicon Model. Feature selection is applied based on COA to select significant data. Ensemble of RNN, VGG-16 and ResNet50classification models are employed to classify the fake news. Experiment results shows that the proposed model achieves 96,23 % accuracy which is higher than other existing models. However DL produces high computational complexity so need to use other models in future.
REFERENCES
1. Ahmad PN, Liu Y, Ali G, Wani MA, ElAffendi M. Robust Benchmark for Propagandist Text Detection and Mining High-Quality Data. Mathematics 2023;11. https://doi.org/10.3390/math11122668.
2. Alarfaj FK, Khan JA. Deep Dive into Fake News Detection: Feature-Centric Classification with Ensemble and Deep Learning Methods. Algorithms 2023;16. https://doi.org/10.3390/a16110507.
3. Ali AA, Latif S, Ghauri SA, Song O-Y, Abbasi AA, Malik AJ. Linguistic Features and Bi-LSTM for Identification of Fake News. Electronics (Switzerland) 2023;12. https://doi.org/10.3390/electronics12132942.
4. Ali AM, Ghaleb FA, Mohammed MS, Alsolami FJ, Khan AI. Web-Informed-Augmented Fake News Detection Model Using Stacked Layers of Convolutional Neural Network and Deep Autoencoder. Mathematics 2023;11. https://doi.org/10.3390/math11091992.
5. Ali H, Khan MS, AlGhadhban A, Alazmi M, Alzamil A, Al-utaibi K, et al. Con-Detect: Detecting adversarially perturbed natural language inputs to deep classifiers through holistic analysis. Computers and Security 2023;132. https://doi.org/10.1016/j.cose.2023.103367.
6. Almarashy AHJ, Feizi-Derakhshi M-R, Salehpour P. Enhancing Fake News Detection by Multi-Feature Classification. IEEE Access 2023;11:139601-13. https://doi.org/10.1109/ACCESS.2023.3339621.
7. Alotaibi W, Alomary F, Mokni R. COVID-19 vaccine rejection causes based on Twitter people’s opinions analysis using deep learning. Social Network Analysis and Mining 2023;13. https://doi.org/10.1007/s13278-023-01059-y.
8. Amado DPA, Diaz FAC, Pantoja R del PC, Sanchez LMB. Benefits of Artificial Intelligence and its Innovation in Organizations. AG Multidisciplinar 2023;1:15-15. https://doi.org/10.62486/agmu202315.
9. Andersen PD, Suhartono D. A Pre-trained Transformer-based Ensemble Model for Automated Indonesian Fake News Classification. International Journal of Intelligent Systems and Applications in Engineering 2023;11:361-7.
10. Assiri F, Himdi H. Comprehensive Study of Arabic Satirical Article Classification. Applied Sciences (Switzerland) 2023;13. https://doi.org/10.3390/app131910616.
11. Awajan A. ENHANCING ARABIC FAKE NEWS DETECTION FOR TWITTERS SOCIAL MEDIA PLATFORM USING SHALLOW LEARNING TECHNIQUES. Journal of Theoretical and Applied Information Technology 2023;101:1745-60.
12. Batista-Mariño Y, Gutiérrez-Cristo HG, Díaz-Vidal M, Peña-Marrero Y, Mulet-Labrada S, Díaz LE-R. Behavior of stomatological emergencies of dental origin. Mario Pozo Ochoa Stomatology Clinic. 2022-2023. AG Odontologia 2023;1:6-6. https://doi.org/10.62486/agodonto20236.
13. Bensouda N, Fkihi SE, Faizi R. A novel ensemble model for detecting fake news. IAES International Journal of Artificial Intelligence 2024;13:1160-71. https://doi.org/10.11591/ijai.v13.i1.pp1160-1171.
14. Caero L, Libertelli J. Relationship between Vigorexia, steroid use, and recreational bodybuilding practice and the effects of the closure of training centers due to the Covid-19 pandemic in young people in Argentina. AG Salud 2023;1:18-18. https://doi.org/10.62486/agsalud202318.
15. Cavalcante L de FB. Feminicide from the perspective of the cultural mediation of information. Advanced Notes in Information Science 2023;5:24-48. https://doi.org/10.47909/978-9916-9906-9-8.72.
16. Chalan SAL, Hinojosa BLA, Claudio BAM, Mendoza OAV. Quality of service and customer satisfaction in the beauty industry in the district of Los Olivos. SCT Proceedings in Interdisciplinary Insights and Innovations 2023;1:5-5. https://doi.org/10.56294/piii20235.
17. Chaudhari D, Pawar AV. Empowering Propaganda Detection in Resource-Restraint Languages: A Transformer-Based Framework for Classifying Hindi News Articles. Big Data and Cognitive Computing 2023;7. https://doi.org/10.3390/bdcc7040175.
18. Chávez JJB, Trujillo REO, Hinojosa BLA, Claudio BAM, Mendoza OAV. Influencer marketing and the buying decision of generation «Z» consumers in beauty and personal care companies. SCT Proceedings in Interdisciplinary Insights and Innovations 2023;1:7-7. https://doi.org/10.56294/piii20237.
19. Choudhry A, Khatri I, Jain M, Vishwakarma DK. An Emotion-Aware Multitask Approach to Fake News and Rumor Detection Using Transfer Learning. IEEE Transactions on Computational Social Systems 2024;11:588-99. https://doi.org/10.1109/TCSS.2022.3228312.
20. De Santis E, Martino A, Rizzi A. Human versus Machine Intelligence: Assessing Natural Language Generation Models through Complex Systems Theory. IEEE Transactions on Pattern Analysis and Machine Intelligence 2024:1-18. https://doi.org/10.1109/TPAMI.2024.3358168.
21. Diaz DPM. Staff turnover in companies. AG Managment 2023;1:16-16. https://doi.org/10.62486/agma202316.
22. Espinosa JCG, Sánchez LML, Pereira MAF. Benefits of Artificial Intelligence in human talent management. AG Multidisciplinar 2023;1:14-14. https://doi.org/10.62486/agmu202314.
23. Farhangian F, Cruz RMO, Cavalcanti GDC. Fake news detection: Taxonomy and comparative study. Information Fusion 2024;103. https://doi.org/10.1016/j.inffus.2023.102140.
24. Figueredo-Rigores A, Blanco-Romero L, Llevat-Romero D. Systemic view of periodontal diseases. AG Odontologia 2023;1:14-14. https://doi.org/10.62486/agodonto202314.
25. Ganpat RR, Ramnath SV. OE-MDL: Optimized Ensemble Machine and Deep Learning for Fake News Detection. International Journal of Intelligent Systems and Applications in Engineering 2024;12:60-85.
26. Gonzalez-Argote J, Castillo-González W. Productivity and Impact of the Scientific Production on Human-Computer Interaction in Scopus from 2018 to 2022. AG Multidisciplinar 2023;1:10-10. https://doi.org/10.62486/agmu202310.
27. Hannah Nithya S, Sahayadhas A. Meta-heuristic Searched-Ensemble Learning for fake news detection with optimal weighted feature selection approach. Data and Knowledge Engineering 2023;144. https://doi.org/10.1016/j.datak.2022.102124.
28. Hernández-Flórez N. Breaking stereotypes: “a philosophical reflection on women criminals from a gender perspective". AG Salud 2023;1:17-17. https://doi.org/10.62486/agsalud202317.
29. Hinojosa BLA, Mendoza OAV. Perceptions on the use of Digital Marketing of the micro-entrepreneurs of the textile sector of the Blue Gallery in the emporium of Gamarra. SCT Proceedings in Interdisciplinary Insights and Innovations 2023;1:9-9. https://doi.org/10.56294/piii20239.
30. Hu L-H, Chen B-Y, Tan S-Q, Li B. Convnext-Upernet Based Deep-Learning Model for Image Forgery Detection and Localization. Jisuanji Xuebao/Chinese Journal of Computers 2023;46:2225-39. https://doi.org/10.11897/SP.J.1016.2023.02225.
31. Jaiswal AK, Srivastava R. Fake region identification in an image using deep learning segmentation model. Multimedia Tools and Applications 2023;82:38901-21. https://doi.org/10.1007/s11042-023-15032-6.
32. Khullar V, Singh HP. f-FNC: Privacy concerned efficient federated approach for fake news classification. Information Sciences 2023;639. https://doi.org/10.1016/j.ins.2023.119017.
33. Kotiyal B, Pathak H, Singh N. Debunking multi-lingual social media posts using deep learning. International Journal of Information Technology (Singapore) 2023;15:2569-81. https://doi.org/10.1007/s41870-023-01288-6.
34. Kozik R, Mazurczyk W, Cabaj K, Pawlicka A, Pawlicki M, Choraś M. Deep Learning for Combating Misinformation in Multicategorical Text Contents. Sensors 2023;23. https://doi.org/10.3390/s23249666.
35. Lamorú-Pardo AM, Álvarez-Romero Y, Rubio-Díaz D, González-Alvarez A, Pérez-Roque L, Vargas-Labrada LS. Dental caries, nutritional status and oral hygiene in schoolchildren, La Demajagua, 2022. AG Odontologia 2023;1:8-8. https://doi.org/10.62486/agodonto20238.
36. Ledesma-Céspedes N, Leyva-Samue L, Barrios-Ledesma L. Use of radiographs in endodontic treatments in pregnant women. AG Odontologia 2023;1:3-3. https://doi.org/10.62486/agodonto20233.
37. Lopez ACA. Contributions of John Calvin to education. A systematic review. AG Multidisciplinar 2023;1:11-11. https://doi.org/10.62486/agmu202311.
38. Luqman M, Faheem M, Ramay WY, Saeed MK, Ahmad MB. Utilizing Ensemble Learning for Detecting Multi-Modal Fake News. IEEE Access 2024;12:15037-49. https://doi.org/10.1109/ACCESS.2024.3357661.
39. Madani M, Motameni H, Mohamadi H. KNNGAN: an oversampling technique for textual imbalanced datasets. Journal of Supercomputing 2023;79:5291-326. https://doi.org/10.1007/s11227-022-04851-3.
40. Marcillí MI, Fernández AP, Marsillí YI, Drullet DI, Isalgué RF. Older adult victims of violence. Satisfaction with health services in primary care. SCT Proceedings in Interdisciplinary Insights and Innovations 2023;1:12-12. https://doi.org/10.56294/piii202312.
41. Marcillí MI, Fernández AP, Marsillí YI, Drullet DI, Isalgué VMF. Characterization of legal drug use in older adult caregivers who are victims of violence. SCT Proceedings in Interdisciplinary Insights and Innovations 2023;1:13-13. https://doi.org/10.56294/piii202313.
42. Men X, Mariano VY. Explainable Fake News Detection Based on BERT and SHAP Applied to COVID-19. International Journal of Modern Education and Computer Science 2024;16:11-22. https://doi.org/10.5815/ijmecs.2024.01.02.
43. Moraes IB. Critical Analysis of Health Indicators in Primary Health Care: A Brazilian Perspective. AG Salud 2023;1:28-28. https://doi.org/10.62486/agsalud202328.
44. Nadeem MI, Ahmed K, Zheng Z, Li D, Assam M, Ghadi YY, et al. SSM: Stylometric and semantic similarity oriented multimodal fake news detection. Journal of King Saud University - Computer and Information Sciences 2023;35. https://doi.org/10.1016/j.jksuci.2023.101559.
45. Nadeem MI, Mohsan SAH, Ahmed K, Li D, Zheng Z, Shafiq M, et al. HyproBert: A Fake News Detection Model Based on Deep Hypercontext. Symmetry 2023;15. https://doi.org/10.3390/sym15020296.
46. Ogolodom MP, Ochong AD, Egop EB, Jeremiah CU, Madume AK, Nyenke CU, et al. Knowledge and perception of healthcare workers towards the adoption of artificial intelligence in healthcare service delivery in Nigeria. AG Salud 2023;1:16-16. https://doi.org/10.62486/agsalud202316.
47. Omar K, Sakr RH, Alrahmawy MF. An ensemble of CNNs with self-attention mechanism for DeepFake video detection. Neural Computing and Applications 2024;36:2749-65. https://doi.org/10.1007/s00521-023-09196-3.
48. Padalko H, Chomko V, Chumachenko D. A novel approach to fake news classification using LSTM-based deep learning models. Frontiers in Big Data 2023;6. https://doi.org/10.3389/fdata.2023.1320800.
49. Palani B, Elango S. BBC-FND: An ensemble of deep learning framework for textual fake news detection. Computers and Electrical Engineering 2023;110. https://doi.org/10.1016/j.compeleceng.2023.108866.
50. Peñaloza JEG, Bermúdez L marcela A, Calderón YMA. Perception of representativeness of the Assembly of Huila 2020-2023. AG Multidisciplinar 2023;1:13-13. https://doi.org/10.62486/agmu202313.
51. Pérez DQ, Palomo IQ, Santana YL, Rodríguez AC, Piñera YP. Predictive value of the neutrophil-lymphocyte index as a predictor of severity and death in patients treated for COVID-19. SCT Proceedings in Interdisciplinary Insights and Innovations 2023;1:14-14. https://doi.org/10.56294/piii202314.
52. Prabhu R, Nashappa CS. A dynamic weight function based BERT auto encoder for sentiment analysis. International Journal of Applied Science and Engineering 2023;21. https://doi.org/10.6703/IJASE.202403_21(1).006.
53. Prado JMK do, Sena PMB. Information science based on FEBAB’s census of Brazilian library science: postgraduate data. Advanced Notes in Information Science 2023;5:1-23. https://doi.org/10.47909/978-9916-9906-9-8.73.
54. Pszona M, Janicka M, Wojdyga G, Wawer A. Towards universal methods for fake news detection. Natural Language Engineering 2023;29:1004-42. https://doi.org/10.1017/S1351324922000456.
55. Pupo-Martínez Y, Dalmau-Ramírez E, Meriño-Collazo L, Céspedes-Proenza I, Cruz-Sánchez A, Blanco-Romero L. Occlusal changes in primary dentition after treatment of dental interferences. AG Odontologia 2023;1:10-10. https://doi.org/10.62486/agodonto202310.
56. Quiroz FJR, Oncoy AWE. Resilience and life satisfaction in migrant university students residing in Lima. AG Salud 2023;1:9-9. https://doi.org/10.62486/agsalud20239.
57. Rao KS, Challa R, Sagar BJJK. Model for Fake News Detection Using AI Technique. International Journal of Safety and Security Engineering 2023;13:121-8. https://doi.org/10.18280/ijsse.130114.
58. Rao S, Verma AK, Bhatia T. Hybrid ensemble framework with self-attention mechanism for social spam detection on imbalanced data. Expert Systems with Applications 2023;217. https://doi.org/10.1016/j.eswa.2023.119594.
59. Roa BAV, Ortiz MAC, Cano CAG. Analysis of the simple tax regime in Colombia, case of night traders in the city of Florencia, Caquetá. AG Managment 2023;1:14-14. https://doi.org/10.62486/agma202314.
60. Rodríguez AL. Analysis of associative entrepreneurship as a territorial strategy in the municipality of Mesetas, Meta. AG Managment 2023;1:15-15. https://doi.org/10.62486/agma202315.
61. Rodríguez LPM, Sánchez PAS. Social appropriation of knowledge applying the knowledge management methodology. Case study: San Miguel de Sema, Boyacá. AG Managment 2023;1:13-13. https://doi.org/10.62486/agma202313.
62. Salh DA, Nabi RM. Kurdish Fake News Detection Based on Machine Learning Approaches. Passer Journal of Basic and Applied Sciences 2023;5:262-71. https://doi.org/10.24271/PSR.2023.380132.1226.
63. Salini Y, Harikiran J. Multiplicative Vector Fusion Model for Detecting Deepfake News in Social Media. Applied Sciences (Switzerland) 2023;13. https://doi.org/10.3390/app13074207.
64. Serra S, Revez J. As bibliotecas públicas na inclusão social de migrantes forçados na Área Metropolitana de Lisboa. Advanced Notes in Information Science 2023;5:49-99. https://doi.org/10.47909/978-9916-9906-9-8.50.
65. Siino M, Tinnirello I, La Cascia M. Is text preprocessing still worth the time? A comparative survey on the influence of popular preprocessing methods on Transformers and traditional classifiers. Information Systems 2024;121. https://doi.org/10.1016/j.is.2023.102342.
66. Solano AVC, Arboleda LDC, García CCC, Dominguez CDC. Benefits of artificial intelligence in companies. AG Managment 2023;1:17-17. https://doi.org/10.62486/agma202317.
67. Srinivasa K, Thilagam PS. Multi-layer perceptron based fake news classification using knowledge base triples. Applied Intelligence 2023;53:6276-87. https://doi.org/10.1007/s10489-022-03627-9.
68. Sultana R, Nishino T. Fake News Detection System using BERT and Boosting Algorithm. International Journal of Computers and their Applications 2023;30:223-34.
69. Tao J, Zhou L, Hickey K. Making sense of the black-boxes: Toward interpretable text classification using deep learning models. Journal of the Association for Information Science and Technology 2023;74:685-700. https://doi.org/10.1002/asi.24642.
70. Truică C-O, Apostol E-S. It’s All in the Embedding! Fake News Detection Using Document Embeddings. Mathematics 2023;11. https://doi.org/10.3390/math11030508.
71. Tufchi S, Yadav A, Ahmed T. A comprehensive survey of multimodal fake news detection techniques: advances, challenges, and opportunities. International Journal of Multimedia Information Retrieval 2023;12. https://doi.org/10.1007/s13735-023-00296-3.
72. Upadhyay R, Pasi G, Viviani M. Vec4Cred: a model for health misinformation detection in web pages. Multimedia Tools and Applications 2023;82:5271-90. https://doi.org/10.1007/s11042-022-13368-z.
73. Verma PK, Agrawal P, Madaan V, Prodan R. MCred: multi-modal message credibility for fake news detection using BERT and CNN. Journal of Ambient Intelligence and Humanized Computing 2023;14:10617-29. https://doi.org/10.1007/s12652-022-04338-2.
74. Wang S, Yang W, Li Z. Towards fake news refuter identification: Mixture of Chi-Merge grounded CNN approach. Expert Systems with Applications 2023;231. https://doi.org/10.1016/j.eswa.2023.120712.
75. Xiong S, Zhang G, Batra V, Xi L, Shi L, Liu L. TRIMOON: Two-Round Inconsistency-based Multi-modal fusion Network for fake news detection. Information Fusion 2023;93:150-8. https://doi.org/10.1016/j.inffus.2022.12.016.
76. Yadav AK, Kumar S, Kumar D, Kumar L, Kumar K, Maurya SK, et al. Fake News Detection Using Hybrid Deep Learning Method. SN Computer Science 2023;4. https://doi.org/10.1007/s42979-023-02296-w.
77. Zaheer H, Bashir M. Detecting fake news for COVID-19 using deep learning: a review. Multimedia Tools and Applications 2024. https://doi.org/10.1007/s11042-024-18564-7.
78. Zhang Q, Guo Z, Zhu Y, Vijayakumar P, Castiglione A, Gupta BB. A Deep Learning-based Fast Fake News Detection Model for Cyber-Physical Social Services. Pattern Recognition Letters 2023;168:31-8. https://doi.org/10.1016/j.patrec.2023.02.026.
FINANCING
There is no funding for this work.
CONFLICT OF INTEREST
The authors declare that there is no conflict of interest.
AUTHORSHIP CONTRIBUTION
Conceptualization: Maheswari RU, Sudha N.
Research: Maheswari RU, Sudha N.
Methodology: Maheswari RU, Sudha N.
Project management: Maheswari RU, Sudha N.
Original drafting-drafting: Maheswari RU, Sudha N.
Writing-revising and editing: Maheswari RU, Sudha N.